
Questions addressed in our work
The Big Picture
Motivation
3D Shape Identification
Mass and Friction Identification
Differentiable Physics Simulation
Identifying Models of Under-actuated Adative Hands
6D Pose Identification
Object Recognition and 6-D Pose Estimation in Clutter (2016 - now)
Problem: Robotic manipulation systems frequently depend on a perception pipeline that can accurately perform object
recognition and six degrees-of-freedom (6-DOF) pose estimation. This is becoming increasingly important as
robots are deployed in environments less structured than traditional automation setups. An example application domain
corresponds to warehouse automation and logistics, as highlighted by the Amazon Robotics Challenge (ARC).
In such tasks, robots have to deal with a large variety of objects potentially placed in complex arrangements, including
cluttered scenes where objects are resting on top of each other and are often only partially visible.
This work considers a similar setup, where a perception system has access to RGB-D images of objects in clutter, as
well as 3D CAD models of the objects, and must provide accurate pose estimation for the entire scene. In this domain,
solutions have been developed that use a Convolutional Neural Network (CNN) for object segmentation, followed by
a 3D model alignment step using point cloud registration techniques for pose estimation. The focus of this project is
improving this last step and increasing the accuracy of pose estimation by reasoning at a scene-level about the physical
interactions between objects.

We also proposed an autonomous process for training CNNs using artificial images. In particular, given access to 3D object models, several aspects of the environment are physically simulated. The models are placed in physically realistic poses with respect to their environment to generate a labeled synthetic dataset. To further improve object detection, the network self-trains over real images that are labeled using a robust multi-view pose estimation process. The key contributions are the incorporation of physical reasoning in the synthetic data generation process and the automation of the annotation process over real images
Results: Experimental results indicate that this process is able to quickly identify in cluttered scenes physically-consistent object poses that are significantly closer to ground truth compared to poses found by point cloud registration methods. The proposed self-training process was also evaluated on several existing datasets and on a dataset that we collected with a Motoman robotic arm. Results show that the proposed approach outperforms popular training processes relying on synthetic - but not physically realistic - data and manual annotation.
Future directions: We are currently expanding this method by using more refined probabilistic segmentation methods, such Fully Convolutional Networks (FCN) for semantic segmentation. We are developing a new pose estimation algorithm that takes as inputs a known model of an object and an R-GBD image of a scene wherein the boundary of the object in question is uncertain and given by the probabilistic output of FCN. The algorithm utilizes the known object model to refine the segmentation and estimate the pose of the object.
Learning Mechanical Models of Unknown Objects Online (2016 - now)
Problem: Identifying mechanical and geometric models of unknown objects online and on the fly, while manipulating them, is key to a successful deployment of robots in unstructured and unknown environments. The goal of this work is to find efficient algorithms for online model identification, and to validate the proposed algorithms on clearing clutters of objects using a real robotic manipulator.
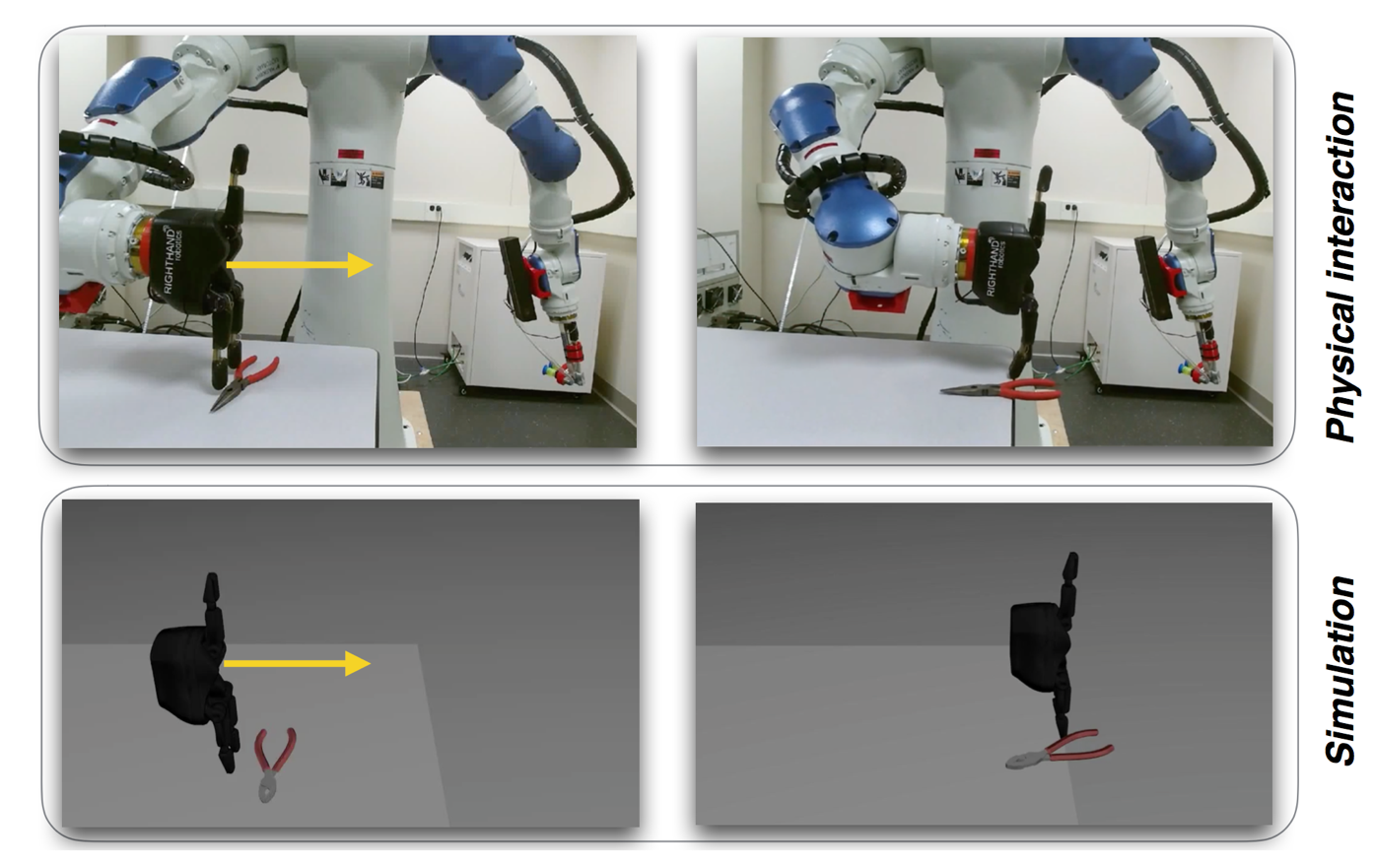
Simulation-Reality Gap
Results: Empirical evaluations, performed in simulation and on a real robotic manipulation task, show that model identification via physics engines can significantly boost the performance of policy search algorithms that are popular in robotics, such as TRPO, PoWER and PILCO, with no additional real-world data. Based on this research, a paper was submitted to ICRA 2018.
Future directions: We are currently performing an analysis of the properties for the proposed method, such as expressing the conditions under which the inclusion of the model identification approach reduces the needs for physical rollouts and the speed-up in convergence in terms of physical rollouts. It is also interesting to consider alternative physical tasks, such as locomotion challenges, which can benefit by the proposed framework.
Apprenticeship Learning of Sequential Manipulation Tasks (2017 - now)
Problem: A major source of failure in robotic manipulation is the
high variety of the objects and their configurations and poses
in such environments. Consequently, a robot needs to be
autonomous and to adapt to changes. However, developing
the software necessary for performing every single new
task autonomously is costly and can be accomplished only
by experienced robotics engineers. This is an issue that is
severely limiting the popularization of robots today.
Ideally, robots should be multi-purpose, polyvalent and
user-friendly machines. For example, factory workers should
be able to train an assistant robot in the same way they
train an apprentice to perform a new task. Humans can successfully
demonstrate how to perform a given task through
vision alone. For instance, a worker records a video showing
how to paint an object and the robot should be able to learn from the video how to plan and execute the task and how
to adapt when the sizes and locations of the brush and paint
bucket vary. This would eventually constitute the ultimate
user-friendly interface for training robots.
Complex manipulation tasks, such as changing a tire, packaging, stacking or painting on a canvas are composed of a sequence of primitive actions such as picking up the brush, dipping it in the paint, and pressing it against the canvas while moving it. A robot can learn to reproduce each of the primitive actions if they were demonstrated separately, using any of the many imitation learning techniques that are available. The main challenge, however, is learning to create a high-level plan from low-level observations. This problem is particularly difficult because the demonstrations are provided as a raw video or a stream of unlabeled images
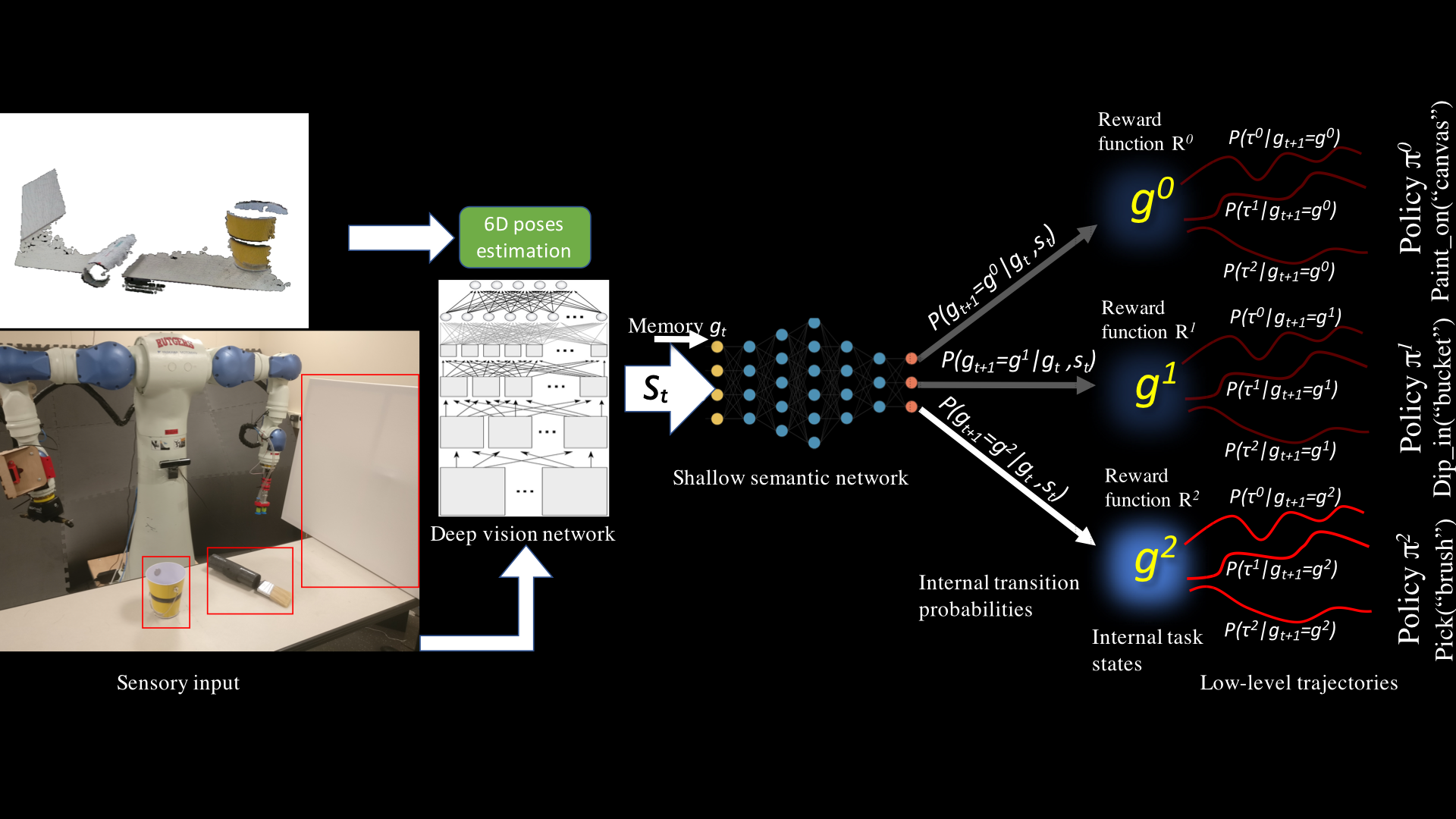
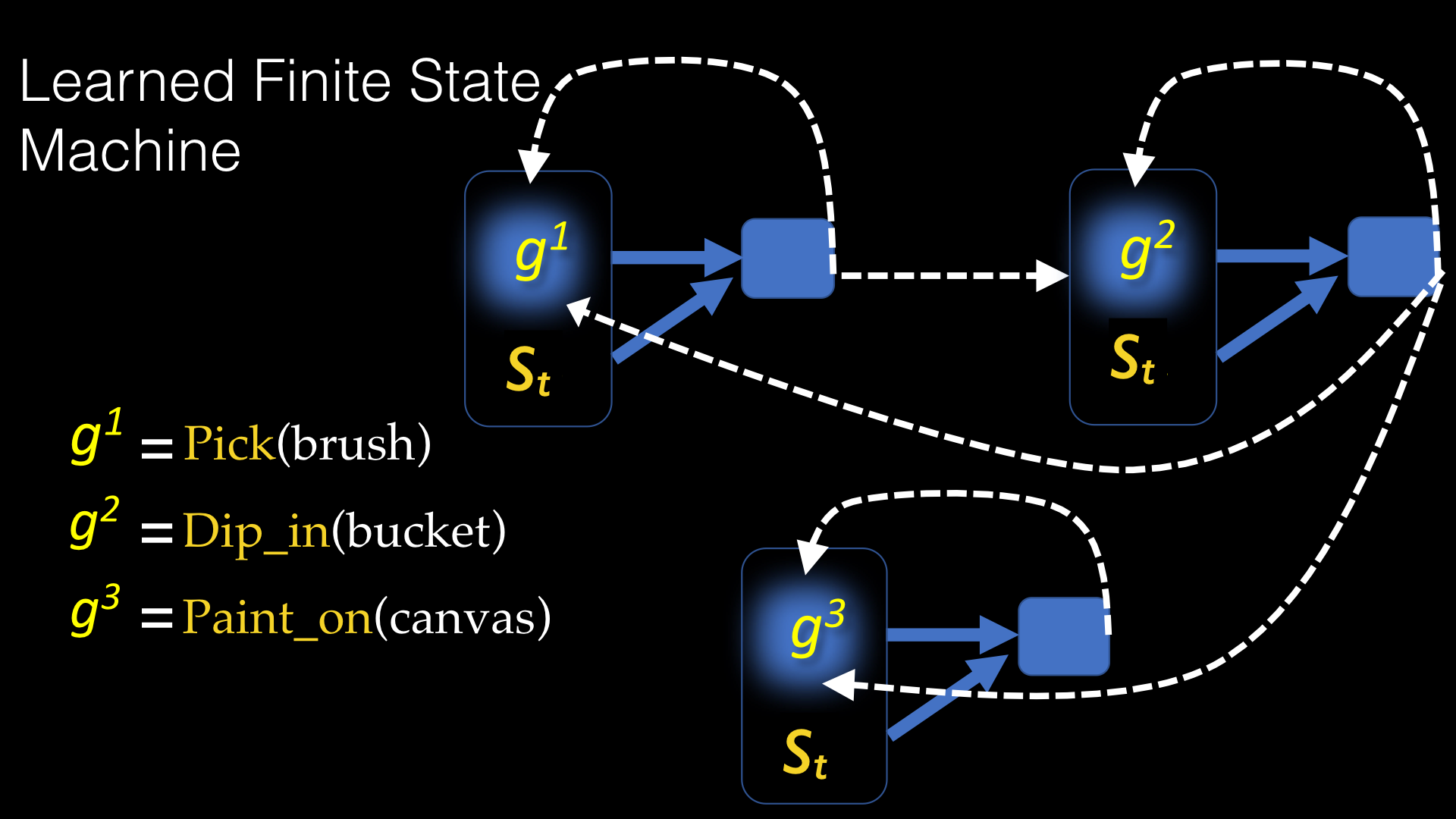
Results: Empirical results on manipulating table-top objects using an industrial robot show that the proposed algorithm can efficiently learn high-level planning strategies from unlabeled visual demonstrations. The algorithm outperforms classical behavioral cloning that learns to map states directly to actions without any reward representation. However, this work still needs to be compared to some recent IRL methods that are becoming increasingly popular.
Future directions: We are investigating new methods for segmenting expert demonstrations into a sequence of subgoals. Currently, we are using the change in the nearest object to expert's hand as an indication of a change in the subgoal, and segment the demonstrations accordingly. The results are rather sensitive to thresholds used for segmentation, especially for tasks with many objects that are near each other. We are also looking into ways to generalize the demonstrated behavior to substantially different setups. Another interesting direction would be incorporating natural language into the framework, where a human could be explaining what she is doing while demonstrating the task.
Other Projects
Learning geometric models of objects in real-time: In this ongoing work, we are interested in constructing 3D mesh and texture models of
objects that are seen by a robot for the first time. The objects are contained in a pile of clutter, and the robot's task is to search for a particular object, or
to clear all the clutter. To achieve that goal, the robot needs to learn on the fly models of the objects in order to effectively manipulate them. This task
is performed by pushing objects in selected directions that maximize the information gain, while continuously tracking the moved objects and reconstructing
full mesh models by combining the observed angles.
Learning to detect objects and predict their movements from raw videos: Based on optical flow in raw outdoor videos, we segment the frames into moving objects. The obtained segments could belong to mobile objects such as humans, cars, and bicycles, or any stationary object that appears to be moving from the perspective of a camera mounted on a robot. The second step consists in clustering the various segments into categories based on their features. Segments that belong to the same category are given the same numerical label by the robot. Finally, a convolutional neural network is trained using the collected and automatically labeled data. This process would allow robots to autonomously learn to detect and recognize objects. The same method could be extended to learn dynamical models of the objects.
Optimal stopping problems in reinforcement learning: Most RL algorithms fall into one of the following two categories: (1) fixed and finite planning horizon, and (2), infinite horizon with a discount factor. Robotic tasks do not typically fit within these categories. They usually require a finite, but variable, time. To throw an object, for example, a robot needs to gain a certain momentum (velocity) at the end-effector by accelerating its arm, and then releases the object at a given moment. Deciding when to switch from one mode of control to another (e.g., from accelerating the arm to releasing the object) can be better formalized by borrowing methods from the optimal stopping literature. We are currently investigating new RL techniques where the planning horizon in itself is a decision variable that needs to be optimized.